Abstract
Light field disparity estimation is an essential task in computer vision. Currently, supervised learning-based methods have achieved better performance than both unsupervised and optimization-based methods. However, the generalization capacity of supervised methods on real-world data, where no ground truth is available for training, remains limited. In this paper, we argue that unsupervised methods can achieve not only much stronger generalization capacity on real-world data but also more accurate disparity estimation results on synthetic datasets. To fulfill this goal, we present the Occlusion Pattern Aware Loss, named OPAL, which successfully extracts and encodes general occlusion patterns inherent in the light field for calculating the disparity loss. OPAL enables: i) accurate and robust disparity estimation by teaching the network how to handle occlusions effectively and ii) significantly reduced network parameters required for accurate and efficient estimation. We further propose an EPI transformer and a gradient-based refinement module for achieving more accurate and pixel-aligned disparity estimation results. Extensive experiments demonstrate our method not only significantly improves the accuracy compared with SOTA unsupervised methods, but also possesses stronger generalization capacity on real-world data compared with SOTA supervised methods. Last but not least, the network training and inference efficiency are much higher than existing learning-based methods.
Method
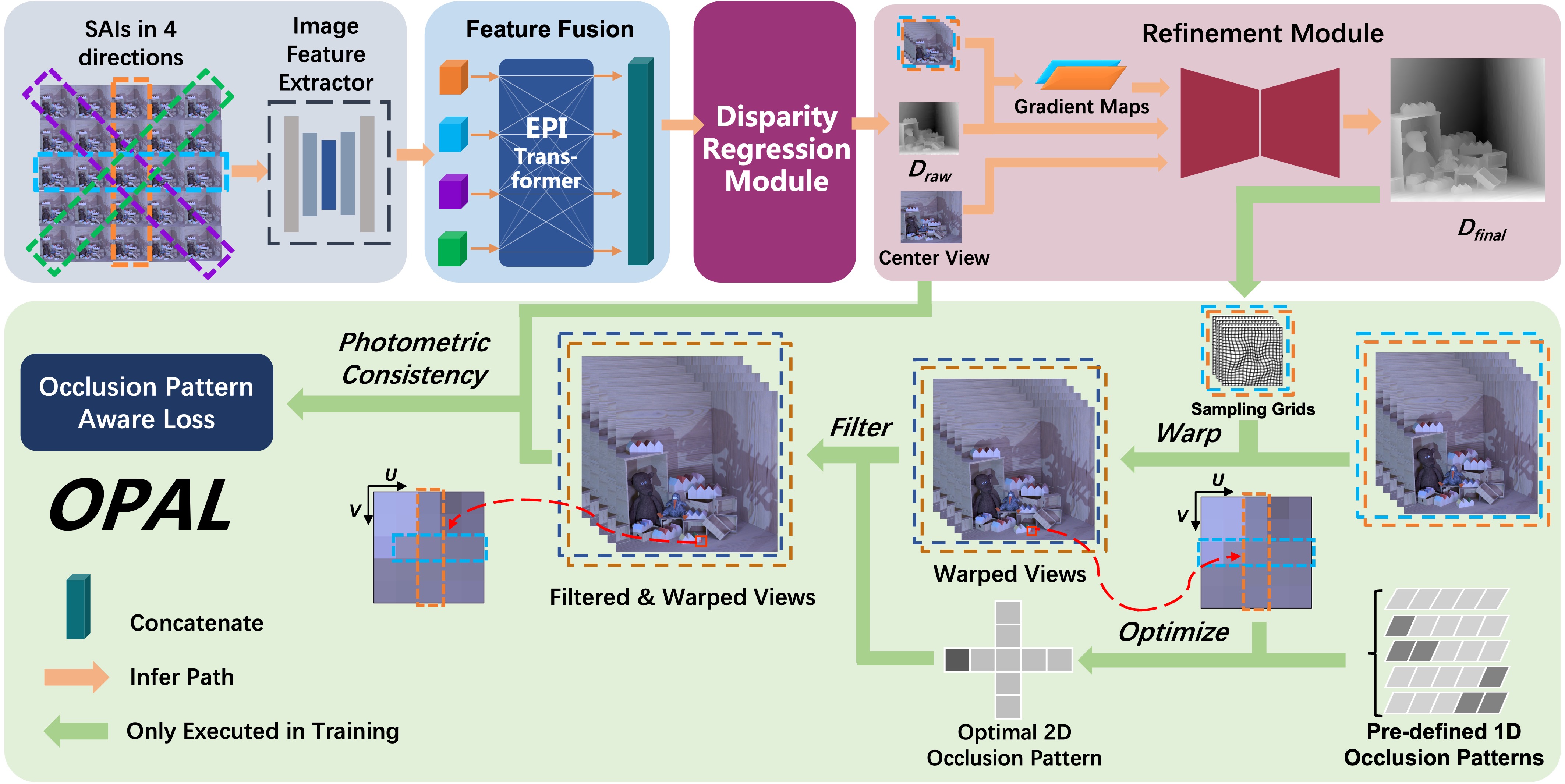 Overview of the network architecture and training loss. Our network, named OPENet, contains four components:
an image feature extractor, an EPI-Transformer, a disparity regression module and a gradient-based disparity refinement
module (GDRM). The green part demonstrates the proposed training loss, OPAL, which is only used for the unsupervised
training process.
Overview of the network architecture and training loss. Our network, named OPENet, contains four components:
an image feature extractor, an EPI-Transformer, a disparity regression module and a gradient-based disparity refinement
module (GDRM). The green part demonstrates the proposed training loss, OPAL, which is only used for the unsupervised
training process.
 Mesh rendering comparisonqs on real-world datasets with SOTA optimization-based (
Mesh rendering comparisonqs on real-world datasets with SOTA optimization-based ( Comparisons of results on realworld dataset captured with Lytro camera. Input, LFattNet, OACC, CAE, OAVC, Unsup and OPAL from left to right.
Comparisons of results on realworld dataset captured with Lytro camera. Input, LFattNet, OACC, CAE, OAVC, Unsup and OPAL from left to right.