Abstract
Creating photorealistic, animatable 3D human avatars from monocular images still largely depends on Linear Blend Skinning (LBS) and parametric body models which constrain expressivity and often introduce artifacts due to imperfect fitting. We propose LUNA, an LBS-free universal neural animation model that directly maps diverse 2D controls like images, keypoints, sketch and unseen characters into 3D Gaussian deformations, bypassing explicit body fitting.
At its core, a transformer-based motion regressor disentangles global rigid motion from fine-grained local dynamics to capture both coherent movement and subtle non-rigid effects. To resolve the inherent ambiguity of 2D-to-3D lifting while scaling beyond fitted datasets, we introduce hybrid supervision that distills soft structural priors from an LBS teacher and a loss that supports training on both limited fitted data and large in-the-wild unlabeled videos. Extensive experiments show LUNA achieves competitive visual fidelity compared to LBS-based approaches, while delivering realistic human motion and zero-shot cross-identity generalization across diverse driving modalities. To the best of our knowledge, LUNA is the first end-to-end 3D animatable model that supports implicit 2D driving.
Method
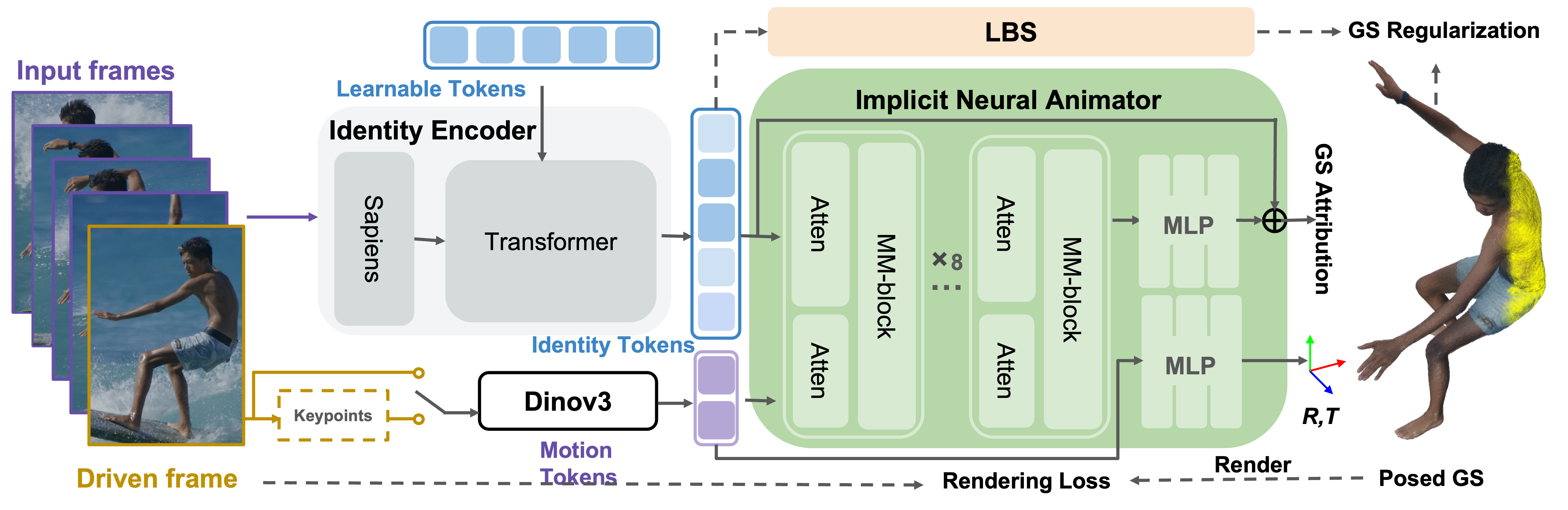
Given N=4 unposed multi-view identity images and a 2D driving signal, LUNA first reconstructs canonical 3D Gaussians with an Identity Encoder. A transformer-based Implicit Neural Animator then maps them to posed space conditioned on the driving signal. During training, the driving image is randomly sampled across modalities (RGB, keypoints or sketches images)