
Input
Generated multiview image and normal maps
Mesh
Abstract
In this paper, we introduce Era3D, a novel multiview diffusion method that generates high-resolution multiview images from a single image. Despite significant advancements in multiview generation, existing methods still suffer from camera prior mismatch, inefficacy, and low resolution resulting in poor-quality multiview images. Specifically, these methods assume that the input images should comply with a predefined camera type, e.g., a perspective camera with a fixed focal length, leading to distorted shapes when the assumption fails. Moreover, the full-image or dense multiview attention they employ leads to an exponential explosion of computational complexity as image resolution increases, resulting in prohibitively expensive training costs. To bridge the gap between assumption and reality, Era3D first proposes a diffusion-based camera prediction module to estimate the focal length and elevation degree of the input image, which allows our method to produce feasible images without shape distortions. Furthermore, a simple but efficient attention layer, named row-wise attention, is used to enforce epipolar priors in the multiview diffusion, facilitating efficient cross-view information fusion. Consequently, compared with state-of-the-art methods, Era3D generates high-quality multiview images with up to a 512×512 resolution while reducing computation complexity by 12x times. Comprehensive experiments demonstrate that Era3D can reconstruct high-quality and detailed 3D meshes from diverse single-view input images, significantly outperforming baseline multiview diffusion methods.
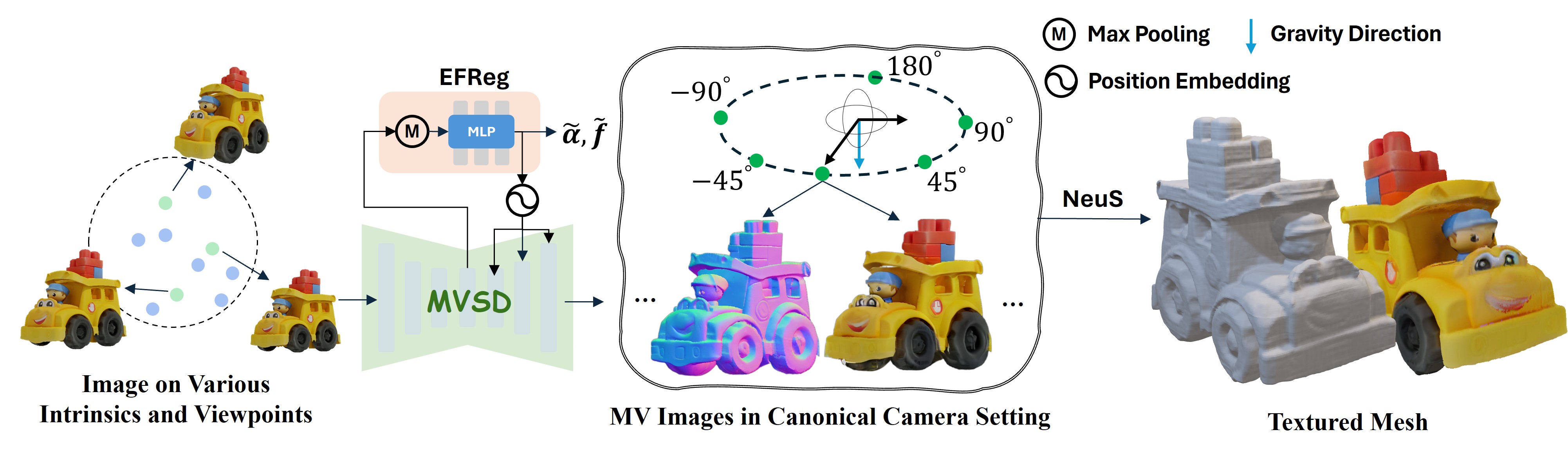
Pipeline. Given a single-view image as input, Era3D applies multiview diffusion to generate multiview consistent images and normal maps in the canonical camera setting, which enables us to reconstruct 3D meshes using neural representations or transformer-based reconstruction methods.
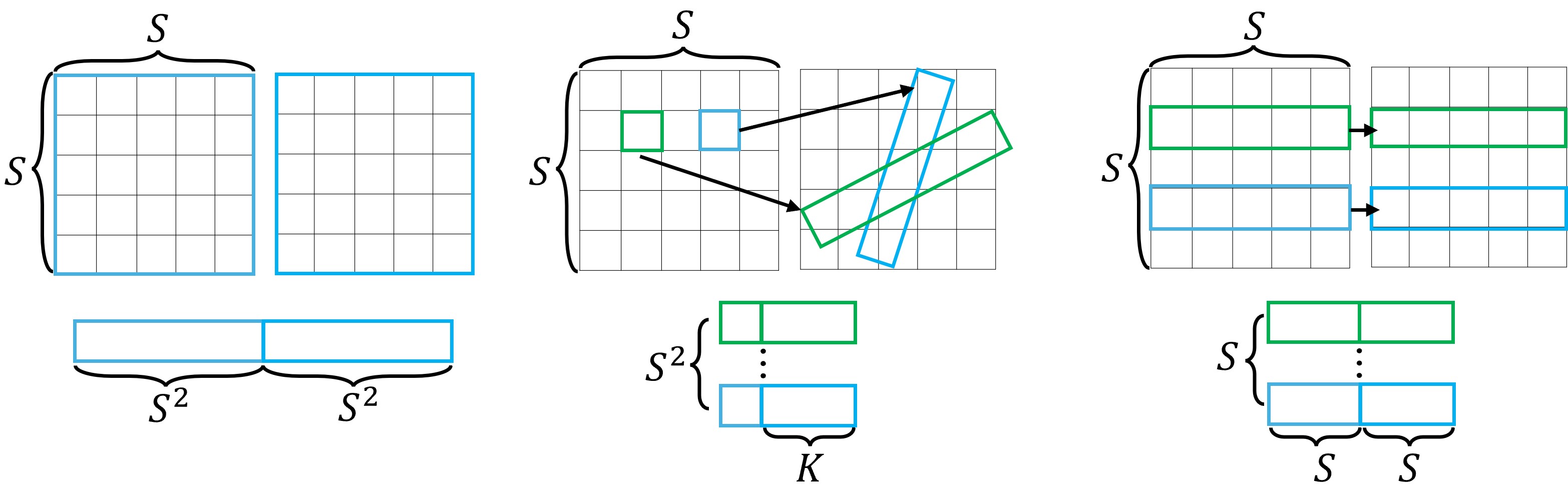
O(N2S4) O(N2S2K) O(N2S3)
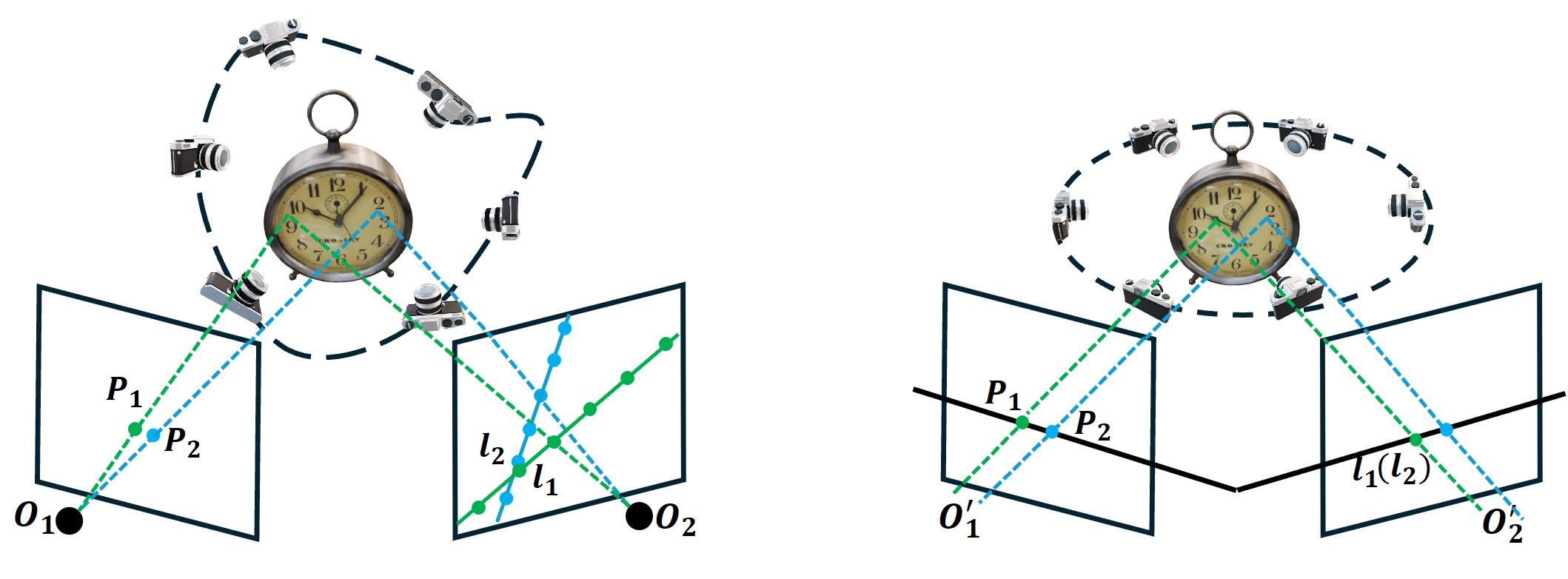
Motivation.
We analyze different types of multiview attention layers. In a dense multiview attention layer (c), all
feature vectors of multiview images are fed into an attention block. For a general camera setting
(a) with arbitrary viewpoints and intrinsics, utilizing epipolar constraint to construct an epipolar
attention (d) needs to correlate the features on the epipolar line. This means that we need to sample
K points along each epipolar line to compute such an attention layer. In our canonical camera setting
(b) with orthogonal cameras and viewpoints on an elevation of 0°, epipolar lines align with the
row of the images across different views (e), which eliminates the need to resample epipolar line
to compute epipolar attention. We assume the latent feature map has a resolution of H × W and
H = W = S. In such a N-view camera system, row-wise attention reduces the computational
complexity to O(N2S3).
A bulldog with a black pirate hat. A pig wearing a backpack. A beautiful cyborg with brown hair. Ghost eating burger. Lewd statue of an angel texting on a cell phone. Kind cartoon lion in costume of astronaut. Cute demon combination angel figure. Dinosaur playing electric guitar. Classic musketeer hat.
This work is mainly supported by Hong Kong Generative AI Research & Development Center (HKGAI) led by Prof. Yike Guo. We are grateful for the necessary GPU resources provided by both Hong Kong University of Science and Technology (HKUST) and DreamTech.
GSO dataset
Text to 3D
Image to 3D
Acknowledgement
BibTeX
@article{li2024era3d,
title={Era3D: High-Resolution Multiview Diffusion using Efficient Row-wise Attention},
author={Li, Peng and Liu, Yuan and Long, Xiaoxiao and Zhang, Feihu and Lin, Cheng and Li, Mengfei and Qi, Xingqun and Zhang, Shanghang and Luo, Wenhan and Tan, Ping and others},
journal={arXiv preprint arXiv:2405.11616},
year={2024}
}